|
|
|
|
Zaval File Search software has multi-tier client-server architecture, where
|
- Back-end of the Zaval File Search is spider which collects all information asynchronously to all user requests;
- Server-side is couple of scripts to produce fast search capabilities inside Apache web server;
- Client side is any browser that recognizes HTML 3.2 or later. CSS and JavaScript support is optional;
In brief, architecture can be displayed as the following picture displays:
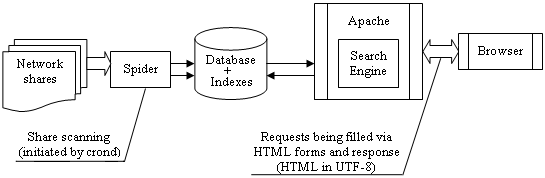
Default configuration contains its own virtual server (usually called search.domain.com) with possibility to provide all available ways to looking up information inside appropriate LAN or WAN.
|
Zaval File Search provides non-standard search capabilities. We've decided to divide search process to the two important stages. There are search of file names without share names, full paths, sizes and other attributes, to make possibility to enumerate only unique names (here we tell "names", because we do not display unique files here); the second stage is display all files relevant to appropriate name being selected.
The design of the search process briefly described above allows providing fastest search for advanced users. Some names and names wildcards are very popular, so the any files corresponding to one name will get a huge list of locations. Authors think the list of dozens of thousands files with the same names but with different places is not an effective way to manage and search files in network; few list with same names is better.
This feature allows users to use non-strict and informal requests for file names with wildcards to provide fastest navigation through the database. The logical operations bring additional flexibility in requests, so users can specify logical operations to wildcards in one request. In additional to two dimensional search Zaval File Search engine allow providing relevant but effective search process.
|
Zaval File Search Spider (also called "spider") is most complex part of Zaval File Search software. It provides full network scanning, including SMB (also known as Microsoft Windows shares) and FTP scanning. Spider works asynchronously to any search requests, so first search request initiated by user wants to operate with fully filled database.
Note: If you want to provide file search service immediately after installation, start scanning process manually with appropriate commands (see documentation for details).
crond (this is well-known tool to start any jobs periodically) starts the spider periodically. Default settings initiates one network scan per day, but system administrators allow managing this period, as they want.
Spider checks all computers have online at time of scanning process; all offline computers will not be indexed. To check this state you can specify network scan period less (please be patient your network allow to scan completely at time period you've used; in other case spider will cause continuous scanning with high network traffic).
All computer shares have scanned sequentially, so you will not get computer slowdown from network scanning process. Several computers will be scanned at once instead to increase scanning process performance. It allows ignoring timeouts from hosts heavily used at time of scanning.
Zaval File Search Spider is capable of providing network scanning at the same time with servicing search requests; this process is safe. All data partially collected during network scanning will not available for any other parts of Zaval File Search software until scanning process completes.
|
|
All information from Zaval File Search spider has been collected into plain text files, not in any known (relational) database. The following reasons have used:
|
- Zaval File Search software supports fully functional regular expressions, and authors have no information about light and fast database with this facility. We know SQL operator 'like' and magic sense of '%';
- Zaval File Search software has no requirements to manage persistent data; so the transactions and referential integrity is not high priority requirements to the database;
- Every search request have passed to the database uses almost all indexes and appropriate content of the files have found, so linear scanning speed is important criteria for us;
Database contains two parts: indexes and file list. Indexes contain brief file names without location, access method, share name and other attributes; they are used to provide first stage of the search. Usually indexes are written to one index file to provide fastest search using regular expressions.
Content of the database (there are file names, full paths, location details, size, date and other attributes stored in the database) are divided into lot of files to provide fast search for corresponding single file name. Usually these files have approximately the same size; these file names are indexes of appropriate hash functions have applied to the brief file names. So, the search all details corresponded to file name have selected (brief file names have looked from indexes file) contains hash function to determine proper database file; and sequential scan inside file have determined.
All file names and corresponding information have collected in UTF-8, so database allows managing any national char set.
|
Zaval File Search Engine (also called "Search engine") requests are submitted using any reasonable browser. Search engine determines all possible options supplied by the user, analyses request to determine which options set, and creates complex regular expression. All requests are converted to regular expressions; this decision allows managing logical operations, user regular expressions, transliteration conversion, and other features via unified search module.
The biggest part of Search engine source code implements option handling and regular expressions creation. The unified engine provides any search via regular expressions; this decision allows providing stage one of the "search process" easy and efficient. Zaval File Search Engine provides two stages both of the search process, and manages user-friendly navigation through these stages. It provides paging, localization and any user interaction with client part.
|
Zaval File Search Client provides user-friendly look and feel, and few JavaScript code to provide user intuitive operations have related to options selection. Default DHTML client of Zaval File Search software allows managing and manipulating user controls in strong relevance of the each other. This part is Internet Explorer / Mozilla specific and is backed by DHTML/CSS usage.
JavaScript can be disabled; it is not a critical part of the Zaval File Search functionality. All necessary checks will be performed also on the server part, so user can access to Zaval File Search functionality through any text browser (Links, Lynx) or via paranoid settings of modern browsers. Even if you have disabled any modern features, Zaval File Search can operate via plain HTML forms without any images, DHTML or JavaScript.
|
For more information about the product, please contact Zaval
CE Group directly in a free form.
Thank you,
The Zaval CE Group.
|
|